ミニ・スーパコンピュータを自作しよう!

本セミナーでは,実際の大規模なスーパコンピュータが採用しているソフトウェア群を用い, 複数台の小型PC (Raspberry Pi) を相互接続した小規模な計算クラスタを構築します. 構築したクラスタ上で並列分散計算を行うアプリケーションを実行し, スーパコンピュータの仕組みを理解します.
説明に用いたスライドは こちら
奈良先端科学技術大学院大学 ソフトウェア設計学研究室
Raspberry Piの操作
本セミナーで用いるRaspberry Piには,LinuxというOperating System (OS) をインストールして使用します (正確には,LinuxをベースにしたRaspbianというOS). Linuxは,みなさんが普段使っているWindowsやmacOSなどのOSとは異なりますが, ほとんどのスーパコンピュータにおいて採用されています. また,ウェブサービスの多くもLinuxの上で動いています.
本章では,Raspbianの操作について簡単に説明します.

ファイルマネージャ
Raspberry Pi上のファイルを操作するためには,ファイルマネージャを使用します. ファイルマネージャは,デスクトップ左上のフォルダのアイコンをクリックすると起動します.
![]()
Windowsのエクスプローラに対応します.
ターミナル
Linuxでは,基本的な操作はGraphical User Interface (GUI) でできますが, より高度・複雑な操作を行う際にはCharacter User Interface (CUI) を用います. CUIによる操作を行うためには,ターミナルというソフトウェアを使用します.
ターミナルを起動するには,デスクトップ左上の黒いウィンドウをクリックします.
![]()
するとターミナルが開きます.ここにコマンドという文字列を入力することでRaspberry Piを操作します.
以下に本セミナーで用いるコマンドを列挙しておきます.
各コマンドの詳細な使用法については,man <コマンド名>や<コマンド名> --help
を参照してください.インターネット上にも多数の解説が存在します.
- ファイル操作
ls: ディレクトリ内のファイルとディレクトリを一覧表示cd: カレントディレクトリを移動pwd: カレントディレクトリを表示mkdir: ディレクトリを作成chmod: ファイル/ディレクトリのアクセス権限を変更cat: ファイルの中身を表示rm: ファイル/ディレクトリを削除cp: ファイル/ディレクトリをコピー
- システム管理
sudo: 後に続くコマンドを管理者権限で実行apt: システムにインストールされているソフトウェアを追加・削除systemctl: システムmount: 外部のファイルシステムをマウントする
- プログラム開発
gcc: コンパイラ (C言語のソースコードを実行可能ファイルに翻訳)mpicc: MPIプログラム用コンパイラmpirun: MPIプログラム用ランチャtime: 後に続くコマンドの実行時間を表示
テキストエディタ
設定ファイルなどのテキストファイルを編集するためには,テキストエディタを使用します. Raspberry PiにはMousepadというエディタがインストールされています. Windowsのメモ帳に対応します.
Mousepadでファイルを編集するには,ターミナル上で下記のコマンドを実行します.
$ mousepad ファイル名
また,編集に管理者権限が必要なファイルを編集するには,sudoと組み合わせます.
$ sudo mousepad ファイル名
クラスタの構築
本セミナーでは,複数台のRaspberry Piを相互接続し,小規模なクラスタを構築します. 構築するクラスタの概要を下図に示します.
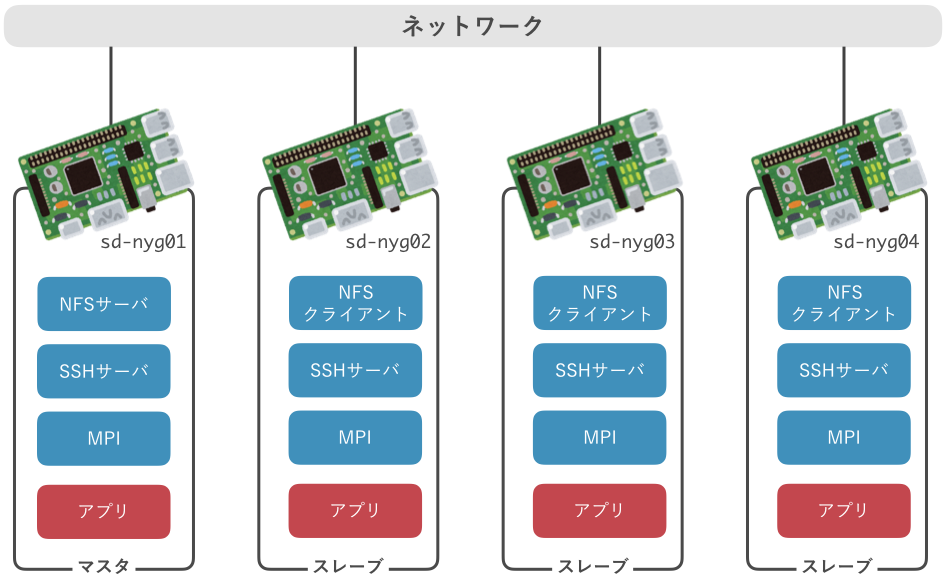
クラスタを構成するコンピュータのことをノードと呼びます. 本クラスタは,1台のマスタ・ノードと3台のスレーブ・ノード,計4台のノードから構成します. マスタは各スレーブを管理し,スレーブはマスタから指示を受けて計算を実行します.
各ノードには,NFS,SSH,MPIの3つのソフトウェアをインストール・設定します. それぞれのソフトウェアの役割は次の通りです.
- マスタからスレーブを操作するための Secure SHell (SSH)
- マスタとスレーブの間でファイルを共有するための Network File System (NFS)
- 全ノードで協調動作し,並列計算を実現するための Message Passing Interface (MPI)
以降の節では,まずRaspberry Pi用のOSであるRaspbianをインストールした後, 各ソフトウェアを順にインストール・設定します.
実際のスパコンでは,今回のクラスタで用いるソフトウェアのほか,
- 計算資源の管理・割当を行うためのジョブスケジューラ
- ノードの状態や障害を監視するための監視・ログ収集基盤
- ノード間で時刻を正確に同期するための時刻同期システム
- ノードのセットアップを自動化する構成管理システム
などのシステムソフトウェアに加え, 多数の科学技術計算用アプリケーションやライブラリがインストールされています.
OSのインストール
この節では,Raspberry Pi向けに最適化された,Raspberry Pi OSというOSをインストールします.
SDカードの準備
-
ライティングソフトの準備: Raspberry Piの公式サイト からRaspberry Pi Imagerをダウンロードし,インストールしてください.
-
ディスクイメージの書き込み: SDカードをPCに接続し,Raspberry Pi Imagerを起動してください. "CHOOSE OS(OSを選ぶ)"でRaspberry Pi OS (32-bit)を選択し, "CHOOSE STORAGE(ストレージを選ぶ)"でSDカードを選択し,"WRITE(書き込む)"を押して書き込みを実行します.

ハードウェアの準備
Raspberry Piの裏面のスロットにディスクイメージを書き込んだSDカードを挿入してください. ディスプレイ,キーボード,マウス,ネットワークケーブルを接続した後,電源を接続してください. 電源のコネクタは汎用のMicro USBもしくはUSB Type-Cですが,消費電流が大きいため,必ず専用のアダプタを使用してください. Raspberry Piには電源ボタンが存在せず,電源を接続すると即座に起動が始まります.

Raspberry Pi OSのインストール
電源を投入すると,Raspberry Piの起動画面が表示された後,Raspberry Pi OSのインストーラが表示されます.
-
初期画面: Nextを押します.
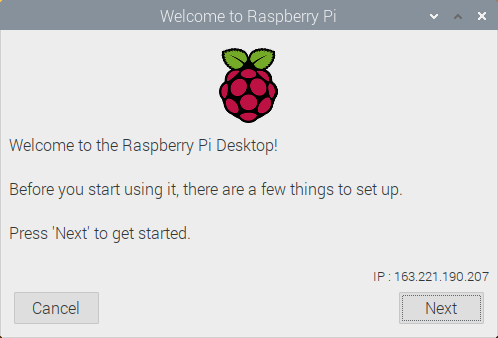
-
Set Country: Countryから"Japan"を選択します.使用しているキーボードがUSレイアウトの場合は,Use US keyboardにチェックを付け,Nextを押します.
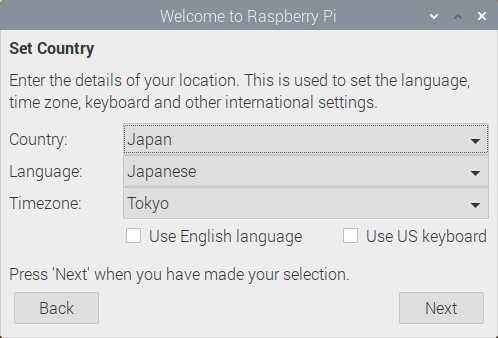
-
Change Password: テキストボックスは空のまま,Nextを押します. (本来はパスワードを変更すべきですが,今回のクラスタは学内からしかアクセス できないので省きます)
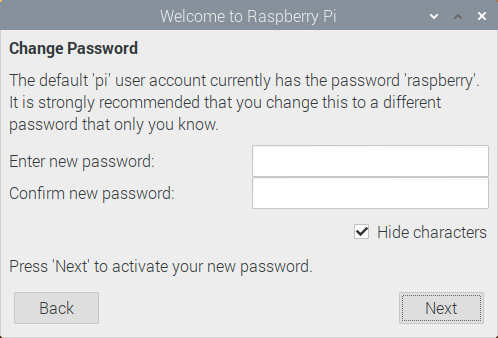
-
Set Up Screen: "This screen shows a black border around the desktop"に チェックを入れ,Nextを押します.
-
Select Wifi Network: Skipを押します. (有線で接続します)
-
Update Software: Skipを押します.
-
Setup Complete: Laterを押します.
ネットワークの設定
ここまでの作業でRaspberry Piは自動的にNAISTのネットワークに接続されています. しかし,NAISTのネットワークから自動的に割り当てられたIPアドレスを使用しているため, 再起動時にIPアドレスが変わる可能性があります.これは後々の設定に不都合なため, 各ノードのIPアドレスを固定します.
まず,IPアドレスを自動設定をするプログラム (dhcpcd) を停止します.
sudo systemctl stop dhcpcd
sudo systemctl disable dhcpcd
次に,/etc/network/interfaces.d/eth0に下記の内容のファイルを新規作成します.
auto eth0
iface eth0 inet static
address XXX.XXX.XXX.XXX
netmask 255.255.255.0
gateway 163.221.190.1
XXX.XXX.XXX.XXXの部分はRaspberry Piごとに下記のように変えてください.
- 1台目:
163.221.190.131 - 2台目:
163.221.190.132 - 3台目:
163.221.190.133 - 4台目:
163.221.190.134
ホスト名を設定します.XXXの部分はRaspberry Piごとに下記のように変えてください.
$ sudo hostnamectl set-hostname XXX
- 1台目:
sd-narakita01.naist.jp - 2台目:
sd-narakita02.naist.jp - 3台目:
sd-narakita03.naist.jp - 4台目:
sd-narakita04.naist.jp
以上でOSのインストール作業は完了です.一度Raspberry Piを再起動してください.
$ sudo reboot
最後に,IPアドレスとホスト名を正しく設定できていことを確認しましょう.
IPアドレスの確認には,ipコマンドを使用します.inetの横に表示されている値が
IPアドレスです.
$ ip address show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether b8:27:eb:ab:5b:6f brd ff:ff:ff:ff:ff:ff
inet 163.221.190.131/24 brd 163.221.190.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet6 fe80::91a8:486b:2b7a:4ff8/64 scope link
valid_lft forever preferred_lft forever
ホスト名の確認には,hostnameコマンドを使用します.
$ hostname
sd-narakita01.naist.jp
CPU周波数の設定
最後に,RasPiの性能を最大限引き出すために,CPUの周波数を最大値で固定しましょう.
$ sudo apt install linux-cpupower
$ sudo cpupower frequency-set -g performance
SSHの設定
この節では,Secure SHell (SSH) を設定します. SSHは遠隔地のコンピュータをネットワークを介して操作するためのソフトウェアです. 今回構築するクラスタでは,マスタから各スレーブ上にプログラムを起動するために使用します.
SSHサーバの起動
SSHによる外部からの操作を受け入れるためには,SSHサーバが起動している必要があります.
まず,各ノードでSSHサーバを起動します.
$ sudo systemctl start ssh
さらに,Raspberry Piが起動した際にSSHサーバが自動起動するよう設定します.
$ sudo systemctl enable ssh
SSHクライアントの設定
SSHクライアントの設定ファイルを作成します.
各ノードで下記の内容のテキストファイルを/home/pi/.ssh/configに作成してください.
Host *
StrictHostKeyChecking no
鍵の生成と転送
SSHは,安全のため,"鍵"を有するコンピュータからのみ操作を受け入れます.そこで,マスタ上で鍵を生成し,これをスレーブに登録することによって,マスタから全てのスレーブを操作できるよう設定します.
まず,マスタ上でSSH鍵を生成します.
$ ssh-keygen
マスタ自身にもこの鍵でログインできるように登録します.
$ ssh-copy-id localhost
次に,生成した鍵を各スレーブに転送します.
$ ssh-copy-id <スレーブのIP>
$ scp /home/pi/.ssh/id_rsa <スレーブのIP>:/home/pi/.ssh/id_rsa
以上でSSHに関する設定は完了です.
NFSの設定
この節では,Network File System (NFS) を設定します. NFSは,異なるコンピュータ間でネットワークを介してファイルを共有するためのソフトウェアです. 今回構築するクラスタでは,実行するプログラムをマスタとスレーブの間で共有するために使用します.
NFSはサーバとクライアントの2種のソフトウェアから構成されます. NFSサーバは,コンピュータ上のファイルを公開するためのソフトウェアです. NFSクライアントはNFSサーバと通信し,NFSサーバが実行されているコンピュータ上のファイルを読み書きします.ここでは,マスタ上でNFSサーバを,スレーブ上でNFSクライアントで実行します.
マスタ
まず,NFS経由でスレーブに対して公開するディレクトリを作成します.
ここでは,/opt/nfsを公開します.
$ sudo mkdir /opt/nfs
$ sudo chmod 777 /opt/nfs
次に,NFSサーバをインストールします.
$ sudo apt install nfs-kernel-server
NFSサーバの設定ファイルを編集し,/opt/nfsを公開する設定を追加します.
/etc/exportsをエディタで開き,下記の行をファイルの末尾に追加します.
/opt/nfs *.naist.jp(rw,sync,no_subtree_check)
追記後のファイルの例:
# /etc/exports: the access control list for filesystems which may be exported
# to NFS clients. See exports(5).
#
# Example for NFSv2 and NFSv3:
# /srv/homes hostname1(rw,sync,no_subtree_check) hostname2(ro,sync,no_subtree_check)
#
# Example for NFSv4:
# /srv/nfs4 gss/krb5i(rw,sync,fsid=0,crossmnt,no_subtree_check)
# /srv/nfs4/homes gss/krb5i(rw,sync,no_subtree_check)
#
/opt/nfs *.naist.jp(rw,sync,no_subtree_check)
NFSサーバに設定ファイルを再読み込みさせます.
$ sudo systemctl reload nfs-server
以上で,マスタにおけるNFSの設定は完了です.
最後に,ファイルを正しく共有できているか確認するために,エディタで/opt/nfs
以下にテスト用のファイルを作成しておきましょう.中身は何でも構いません.
スレーブ
NFSクライアントをインストールします.
$ sudo apt install nfs-common
マウントポイントを作成します.
$ sudo mkdir /opt/nfs
マスタのディレクトリをスレーブからアクセス可能にします.
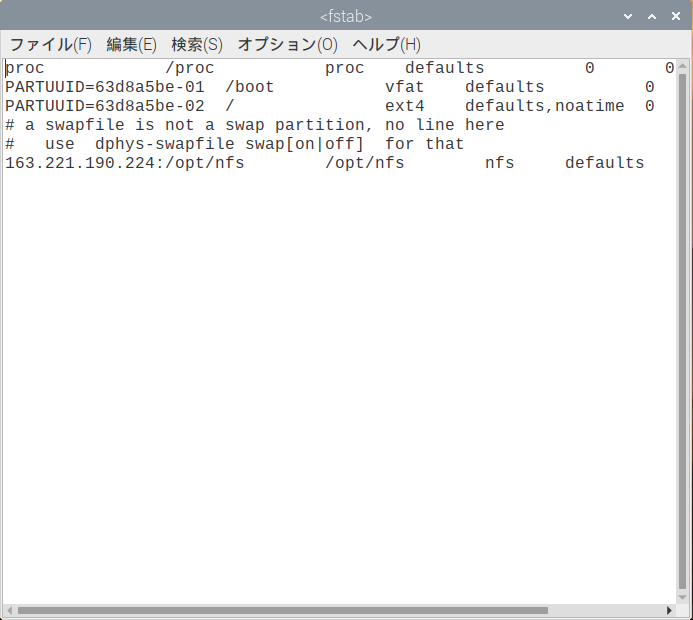
/etc/fstabを編集し,下記の行をファイルの末尾に追加します.
sd-narakita01.naist.jp:/opt/nfs /opt/nfs nfs defaults 0 0
追記後のファイルの例:
proc /proc proc defaults 0 0
PARTUUID=63d8a5be-01 /boot vfat defaults 0 2
PARTUUID=63d8a5be-02 / ext4 defaults,noatime 0 1
# a swapfile is not a swap partition, no line here
# use dphys-swapfile swap[on|off] for that
sd-narakita01.naist.jp:/opt/nfs /opt/nfs nfs defaults 0 0
/etc/fstabの設定を反映させます.
$ sudo mount -a
以上で,スレーブにおけるNFSの設定は完了です.
マスタで/opt/nfsに作成したファイルが,スレーブから見えるか確認しましょう.
Note: NFSでは,スレーブの数が増えるとマスタの負荷が増大し,ファイルの 読み書きが遅くなってしまうという問題があります.そのため, 大規模なスパコンでは,負荷を複数のコンピュータに分散する 並列ファイルシステムが使用されています. (LustreやGPFSなど)
MPIの設定
この節では,Message Passing Interface (MPI) をインストールします. MPIは並列分散計算のためのソフトウェアで,複数のコンピュータ上で並列に実行される プログラムが協調動作することを可能にします.
MPIには様々な実装が存在しますが,今回はオープンソースであり,広く使用されている Open MPIを採用します. SSHとNFSが動作の前提となるので, これらが正しく設定できていることを確認しておいてください.
設定
まず,Open MPIを各ノードでインストールします.
$ sudo apt install openmpi-bin libopenmpi-dev
次に,hostファイルをマスタノードで作成します.Hostファイルは,クラスタを構成するコンピュータ
のアドレスをMPIに教えてあげるためのものです.次の内容のテキストファイルを,
/opt/nfs/hostsという名前で作成してください.
sd-narakita01.naist.jp
sd-narakita02.naist.jp
sd-narakita03.naist.jp
sd-narakita04.naist.jp
動作確認
簡単なMPIプログラムを実行し,MPIが正しく動作することを確認しましょう. 以下の操作は全てマスタ上で行います.
下記のソースコードを/opt/nfs/hello.cというファイル名で作成してください.
(MPI Tutorialより抜粋)
#include <mpi.h>
#include <stdio.h>
int main(int argc, char** argv) {
// MPIを初期化
MPI_Init(NULL, NULL);
// 全プロセス数 (≒クラスタ内のコア数) を取得
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
// このプロセスのランク (プロセスID) を取得
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
// このノードのホスト名を取得
char processor_name[MPI_MAX_PROCESSOR_NAME];
int name_len;
MPI_Get_processor_name(processor_name, &name_len);
// Hello worldを出力
printf("Hello world from processor %s, rank %d out of %d processors\n",
processor_name, world_rank, world_size);
// MPIを終了
MPI_Finalize();
}
次に,hello.cをMPI用コンパイラでコンパイルし,実行可能ファイルを作成します.
$ cd /opt/nfs
$ mpicc -o hello hello.c
MPIプログラム用ランチャでプログラムを起動します. 下記のように出力されれば成功です.(表示は順不同です)
$ mpirun --hostfile hosts ./hello
Hello world from processor sd-narakita01, rank 2 out of 16 processors
Hello world from processor sd-narakita01, rank 0 out of 16 processors
Hello world from processor sd-narakita01, rank 3 out of 16 processors
Hello world from processor sd-narakita04, rank 14 out of 16 processors
Hello world from processor sd-narakita04, rank 12 out of 16 processors
Hello world from processor sd-narakita03, rank 8 out of 16 processors
Hello world from processor sd-narakita04, rank 15 out of 16 processors
Hello world from processor sd-narakita03, rank 9 out of 16 processors
Hello world from processor sd-narakita02, rank 7 out of 16 processors
Hello world from processor sd-narakita03, rank 10 out of 16 processors
Hello world from processor sd-narakita02, rank 5 out of 16 processors
Hello world from processor sd-narakita04, rank 13 out of 16 processors
Hello world from processor sd-narakita03, rank 11 out of 16 processors
Hello world from processor sd-narakita02, rank 6 out of 16 processors
Hello world from processor sd-narakita01, rank 1 out of 16 processors
Hello world from processor sd-narakita02, rank 4 out of 16 processors
この出力を見ると,
sd-narakita01からsd-narakita04までの4ノード上でプロセスが起動している- ランク0から15までの計16プロセスが起動している
- ランク0から3までの4プロセスが
sd-narakita01で,ランク1から5がsd-narakita02で,…という風に,1ノードあたり4プロセスずつ起動している
などがわかります.
スパコンプログラミングの基礎
この章では,ベクトルの内積を求めるプログラムを例に, スーパコンピュータにおけるプログラミングの基礎を説明します.
サンプルプログラム
下記のソースコードは,100万次元のベクトルaとbの内積を1,000回求めるプログラムです. この計算自体には意味はありませんが,内積をはじめとする様々な線形代数の演算は, シミュレーションや機械学習に欠かせません.
本ソースコードでは,配列aとbはそれぞれベクトルaとbに対応し,
内積の計算はcompute()関数の中で実行しています.
forループの中で配列aとbの要素を1つずつ掛け合わせ,その結果を変数sumに積算しています.
#include <stdio.h>
#define TRIALS (1000)
#define ARRAY_SIZE (1000 * 1000)
// ARRAY_SIZE個の要素を持つ配列aとbを定義
double a[ARRAY_SIZE];
double b[ARRAY_SIZE];
// 内積を計算する関数
void compute()
{
double sum = 0;
// aのi番目の要素とbのi番目の要素を乗算し,sumに加算
for (int i = 0; i < ARRAY_SIZE; i++) {
sum += a[i] * b[i];
}
}
// プログラムの開始地点となる関数
int main(int argc, char *argv[])
{
// 配列aとbを初期化
for (int i = 0; i < ARRAY_SIZE; i++) {
a[i] = 1.0;
b[i] = 2.0;
}
// 内積計算をTRIALS回繰り返す
for (int i = 0; i < TRIALS; i++) {
compute();
}
return 0;
}
実行時間の計測
まずは,このプログラムを実行し,実行時間を計測してみましょう.
上記のプログラムをdot.cというファイル名で保存した後,下記のコマンドで
コンパイルします.
$ gcc -o dot dot.c
生成された実行ファイルを実行します.timeは,後に続くコマンドの実行時間を
計測するコマンドです.
$ time ./dot
約27秒かかりました.
real 0m26.886s
user 0m26.824s
sys 0m0.060s
このプログラムは1つのRaspberry Pi上の1つのCPUコアしか活用できません. 以降ではこのプログラムを並列化し,複数のRaspberry Pi上の複数のCPUコアを利用することで,高速化します.
参考文献
ノード内並列
まずは,内積計算プログラムが1つのRaspberry Pi上の複数のCPUコアを利用できるよう に拡張しましょう.これを,ノード内並列化と呼びます.
OpenMPとは
複数のCPUコアを活用するには様々な方法がありますが,スパコンにおいて広く 用いられているのは,OpenMPと呼ばれるAPIです. OpenMPに対応するコンパイラを用いると,ソースコード中にディレクティブと 呼ばれるコメントのようなものを挿入するだけで, コンパイラが自動的に並列化しててくれます.
下記がOpenMPを用いて並列化した内積計算プログラムです.
逐次版のソースコードに追加したのは,
#pragma omp parallel for reduction(+:sum)という1行だけです.
このディレクティブを挿入することにより,直後のforループが自動的にコアの数に分割され,
並列に実行されます.
例えば,ARRAY_SIZEが100でCPUが4コアだとすると,
- コア0が
i=0〜24 - コア1が
i=25〜49 - コア2が
i=50〜74 - コア3が
i=75〜99
という風に4つのコアがループを均等に分担して実行します.
#include <stdio.h>
#define TRIALS (1000)
#define ARRAY_SIZE (1000 * 1000)
double a[ARRAY_SIZE];
double b[ARRAY_SIZE];
void compute()
{
double sum = 0;
#pragma omp parallel for reduction(+:sum)
for (int i = 0; i < ARRAY_SIZE; i++) {
sum += a[i] * b[i];
}
}
int main(int argc, char *argv[])
{
for (int i = 0; i < ARRAY_SIZE; i++) {
a[i] = 1.0;
b[i] = 2.0;
}
for (int i = 0; i < TRIALS; i++) {
compute();
}
return 0;
}
OpenMP版プログラムのコンパイル・実行
このプログラムをgccコンパイラでコンパイルします.
OpenMPを使用するプログラムするためには,-fopenmpというオプションを指定する必要があります.
$ gcc -fopenmp -o dot_omp dot_omp.c
このプログラムを実行します.
$ time ./dot_omp
OpenMPを使用しない場合の26.886秒に対して,7.372秒に実行時間を短縮できました. Raspberry Pi 3B+は4つのCPUコアを搭載しています.4つのCPUコアを活用することで, 3.6倍の高速化を達成できたことになります.
real 0m7.372s
user 0m29.175s
sys 0m0.040s
OpenMPはデフォルトでは全てのCPUコアを用いて計算を行いますが,
OMP_NUM_THREADSという環境変数を設定することにより,使用するコア数を制限することができます.
例えば,2コアを使用して計算を行うためには,次のようにします.
$ time OMP_NUM_THREADS=2 ./dot_omp
やってみよう
OMP_NUM_THREADSを使用して使用するコア数を1から4まで変更し, プログラムの実行時間がどのように変化するか調べてみましょう.ARRAY_SIZEやTRIALSをより大きな値に変更して,実行時間を測ってみましょう.
ノード間並列
ここでは,内積計算プログラムが複数のRaspberry Pi上の複数のCPUコアを利用できるよう 拡張しましょう.これを,ノード間並列化と呼びます.
MPIとは
ノード内並列化と同様に,ノード間並列化にも様々な方法がありますが, スパコンにおいて広く用いられているのは,MPIと呼ばれるAPIです.
#include <stdio.h>
#include <mpi.h>
#define TRIALS (1000)
#define ARRAY_SIZE (1000 * 1000)
double a[ARRAY_SIZE];
double b[ARRAY_SIZE];
void compute()
{
int rank, nprocs;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &nprocs);
double sum = 0;
int subarray_size = ARRAY_SIZE / nprocs;
for (int i = subarray_size * rank; i < subarray_size * (rank + 1); i++) {
sum += a[i] * b[i];
}
double sum_total;
MPI_Reduce(&sum, &sum_total, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
}
int main(int argc, char *argv[])
{
MPI_Init(&argc, &argv);
for (int i = 0; i < ARRAY_SIZE; i++) {
a[i] = 1.0;
b[i] = 2.0;
}
for (int i = 0; i < TRIALS; i++) {
compute();
}
MPI_Finalize();
return 0;
}
MPI版プログラムのコンパイル・実行
このプログラムをMPI用コンパイラでコンパイルします.
$ mpicc -o dot_mpi dot_mpi.c
MPIプログラム用ランチャでプログラムを起動し,実行時間を計測します.
$ time mpirun --hostfile hosts dot_mpi
OpenMPを使用しない場合の26.886秒に対して,3.377秒に実行時間を短縮できました. 4ノード上の計16のCPUコアを活用することで, 8.0倍の高速化を達成できたことになります.
real 0m3.377s
user 0m8.979s
sys 0m0.851s
MPIはデフォルトでは全てのノードの全てのCPUコアを用いて計算を行います.
mpirunに-npというオプションを指定することにより,
使用するコア数を制限することができます.
例えば,8コアを使用して計算を行うためには,次のようにします.
$ time mpirun -np 8 --hostfile hosts dot_mpi
やってみよう
-npオプションを用いて使用するコア数を変更し,プログラムの実行時間がどのように変化するか調べてみましょう.
演習
円周率計算
下記のソースコードは,モンテカルロ法によって円周率の近似値を求めるためのプログラムです.
#include <math.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define N (100 * 1000 * 1000)
static struct timespec diff(struct timespec start, struct timespec end)
{
struct timespec ts;
if (end.tv_nsec - start.tv_nsec < 0) {
ts.tv_sec = end.tv_sec - start.tv_sec - 1;
ts.tv_nsec = 1000000000 + end.tv_nsec - start.tv_nsec;
} else {
ts.tv_sec = end.tv_sec - start.tv_sec;
ts.tv_nsec = end.tv_nsec - start.tv_nsec;
}
return ts;
}
static void compute()
{
// 原点を中心とする半径1の円に含まれる点の個数
long long count = 0;
double x, y;
struct drand48_data buffer;
struct timespec ts;
// 疑似乱数生成器を現在時刻で初期化
clock_gettime(CLOCK_MONOTONIC, &ts);
srand48_r(ts.tv_nsec, &buffer);
// 計N個の点を生成する
for (int i = 0; i < N; i++) {
// [0, 1)の範囲の乱数を生成し,xとyに代入
drand48_r(&buffer, &x);
drand48_r(&buffer, &y);
// (x, y)が原点を中心とする半径1の円に含まれるなら
if (x * x + y * y < 1.0) {
// countを1増やす
count++;
}
}
// 円周率の近似値を表示
double pi = 4.0 * count / N;
printf("estimated pi = %lf\n", pi);
// 近似値の真値からの誤差を表示
printf("error = %lf\n", fabs(pi - M_PI));
}
int main(int argc, char *argv[])
{
struct timespec start_ts, end_ts;
clock_gettime(CLOCK_MONOTONIC, &start_ts);
compute();
clock_gettime(CLOCK_MONOTONIC, &end_ts);
struct timespec elapsed_ts = diff(start_ts, end_ts);
printf("elapsed: %ld.%09ld [s]\n", elapsed_ts.tv_sec,
elapsed_ts.tv_nsec);
return 0;
}
具体的なアルゴリズムは次の通りです. 1x1の正方形内にランダムに点を打ち,半径1の円の中に含まれる点の個数を数えます. 円に含まれるの点の数を全ての点の数で割ると,4分の1円の面積の近似値が求まります. これを4倍すると,円周率の近似値が得られます.上の例では, 10億個の点を打っています.
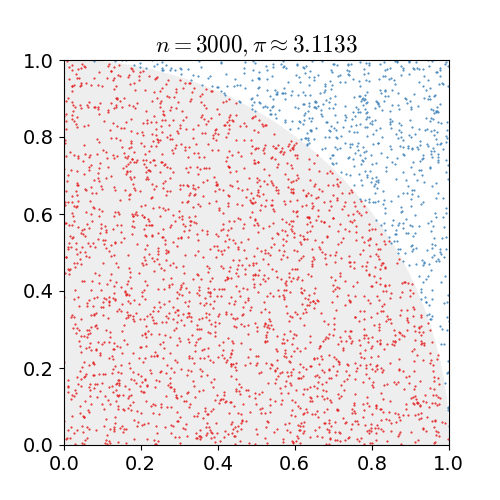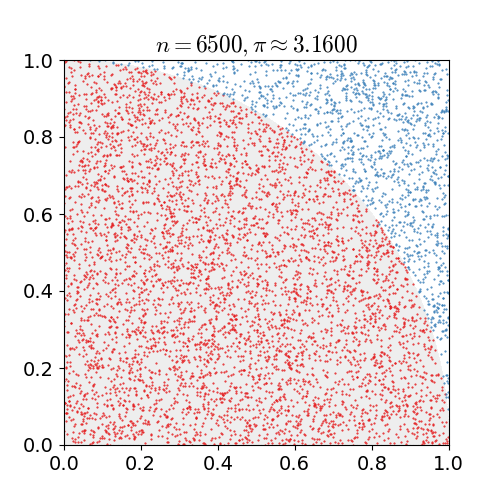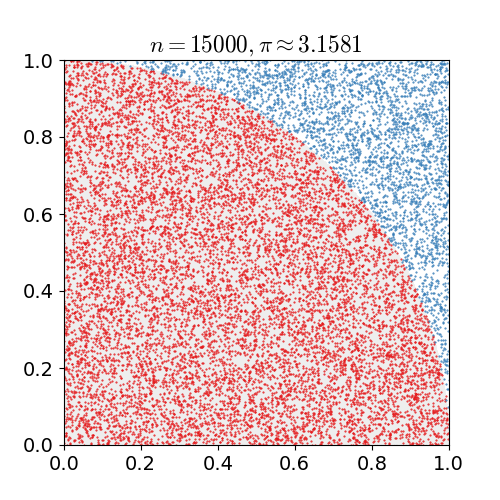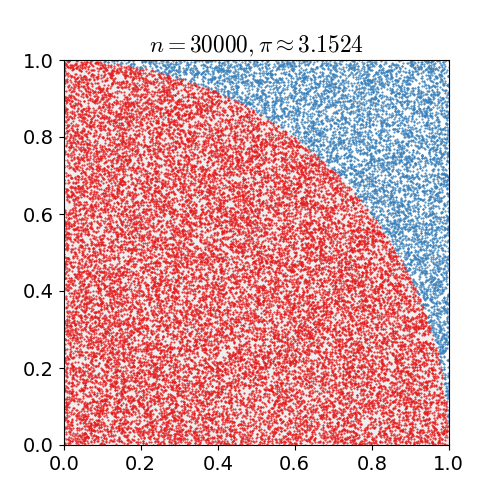 nicoguaro CC BY 3.0
nicoguaro CC BY 3.0
やってみよう
- このプログラムをノード内並列化してみましょう.
- このプログラムをノード間並列化してみましょう.
熱伝導シミュレーション
下記のソースコードは,有限差分法によって熱伝導方程式をシミュレーションするためのプログラムです.
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <unistd.h>
struct simulator {
int n;
float *T1;
float *T2;
int tmax;
float alpha;
float w1;
float w2;
float dx;
float dt;
};
static struct timespec diff(struct timespec start, struct timespec end)
{
struct timespec ts;
if (end.tv_nsec - start.tv_nsec < 0) {
ts.tv_sec = end.tv_sec - start.tv_sec - 1;
ts.tv_nsec = 1000000000 + end.tv_nsec - start.tv_nsec;
} else {
ts.tv_sec = end.tv_sec - start.tv_sec;
ts.tv_nsec = end.tv_nsec - start.tv_nsec;
}
return ts;
}
static void write_result(struct simulator *sim, int step)
{
char fname[32];
sprintf(fname, "result_%d.csv", step);
FILE *fd = fopen(fname, "w");
fprintf(fd, "x,y,T\n");
for (int y = 1; y <= sim->n; y++) {
for (int x = 1; x <= sim->n; x++) {
fprintf(fd, "%f,%f,%f\n", (x - 1) * sim->dx, (y - 1) * sim->dx,
sim->T1[x + y * (sim->n + 2)]);
}
}
fclose(fd);
}
static void step(struct simulator *sim)
{
for (int y = 1; y <= sim->n; y++) {
for (int x = 1; x <= sim->n; x++) {
sim->T2[x + y * (sim->n + 2)] =
sim->w1 * sim->T1[x + y * (sim->n + 2)] +
sim->w2 * (sim->T1[(x - 1) + y * (sim->n + 2)] +
sim->T1[x + (y - 1) * (sim->n + 2)] +
sim->T1[(x + 1) + y * (sim->n + 2)] +
sim->T1[x + (y + 1) * (sim->n + 2)]);
}
}
float *tmp = sim->T2;
sim->T2 = sim->T1;
sim->T1 = tmp;
}
static void compute(struct simulator *sim)
{
for (int i = 0; i < sim->tmax; i++) {
step(sim);
if (i % 10 == 0) {
printf("Writing out step %d\n", i);
write_result(sim, i);
}
}
}
static void print_settings(struct simulator *sim)
{
printf("grid size: %dx%d\n", sim->n, sim->n);
printf("tmax: %d\n", sim->tmax);
printf("alpha: %f\n", sim->alpha);
printf("delta x: %f\n", sim->dx);
printf("delta t: %f\n", sim->dt);
}
static void initialize(struct simulator *sim)
{
for (int y = 0; y <= sim->n + 1; y++) {
for (int x = 0; x <= sim->n + 1; x++) {
float temp = 50.0f;
if (x == 0 || y == 0) {
temp = 0.0f;
} else if (x == sim->n + 1 || y == sim->n + 1) {
temp = 100.0f;
}
sim->T1[x + y * (sim->n + 2)] = temp;
sim->T2[x + y * (sim->n + 2)] = temp;
}
}
}
int main(int argc, char *argv[])
{
int ch;
int n = 100, tmax = 100;
while ((ch = getopt(argc, argv, "t:n:")) != -1) {
switch (ch) {
case 'n':
n = atoi(optarg);
break;
case 't':
tmax = atoi(optarg);
break;
case 'h':
default:
fprintf(stderr, "Usage: %s -n <size>\n", argv[0]);
break;
}
}
struct simulator sim;
sim.n = n;
sim.T1 = (float *)calloc((n + 2) * (n + 2), sizeof(float));
sim.T2 = (float *)calloc((n + 2) * (n + 2), sizeof(float));
sim.tmax = tmax;
sim.alpha = 0.1f;
sim.dx = 0.01f;
sim.dt = 0.0001f;
sim.w1 = 1.0f - (4.0f * sim.alpha * sim.dt) / (sim.dx * sim.dx);
sim.w2 = (sim.alpha * sim.dt) / (sim.dx * sim.dx);
print_settings(&sim);
initialize(&sim);
struct timespec start_ts, end_ts;
clock_gettime(CLOCK_MONOTONIC, &start_ts);
compute(&sim);
clock_gettime(CLOCK_MONOTONIC, &end_ts);
struct timespec elapsed_ts = diff(start_ts, end_ts);
printf("elapsed: %ld.%09ld [s]\n", elapsed_ts.tv_sec,
elapsed_ts.tv_nsec);
return 0;
}
やってみよう
- このプログラムをコンパイルし,実行してみましょう.
- ParaViewを用いて,出力されたCSVファイルを可視化してみましょう.
- 初期条件を変更し,シミュレーション結果がどのように変わるか調べてみましょう.
ParaViewの使い方
ParaViewを公式サイトからダウンロードし,インストールします. ParaViewを起動すると,次のような画面が表示されます.
画面左上の "Open" ボタンをクリックし,シミュレータが出力したCSVファイルを選択しましょう.
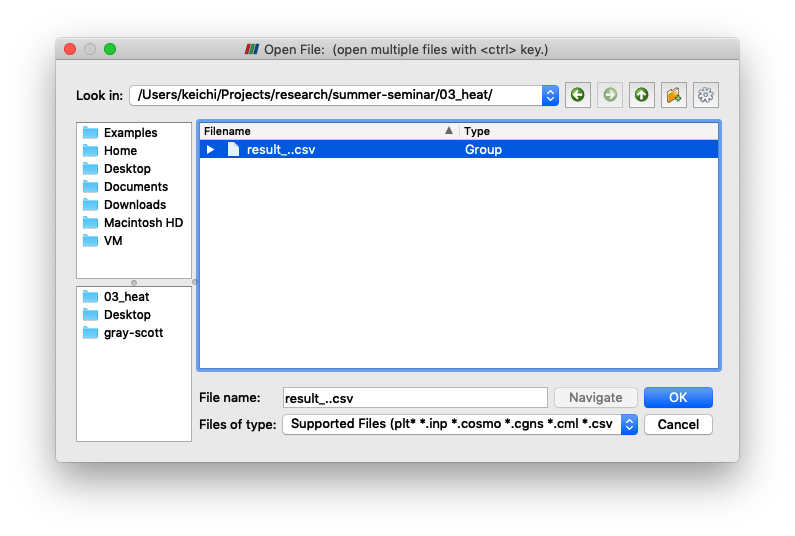
ウィンドウ左下の "Properties" タブにある "Apply" ボタンを押してください.
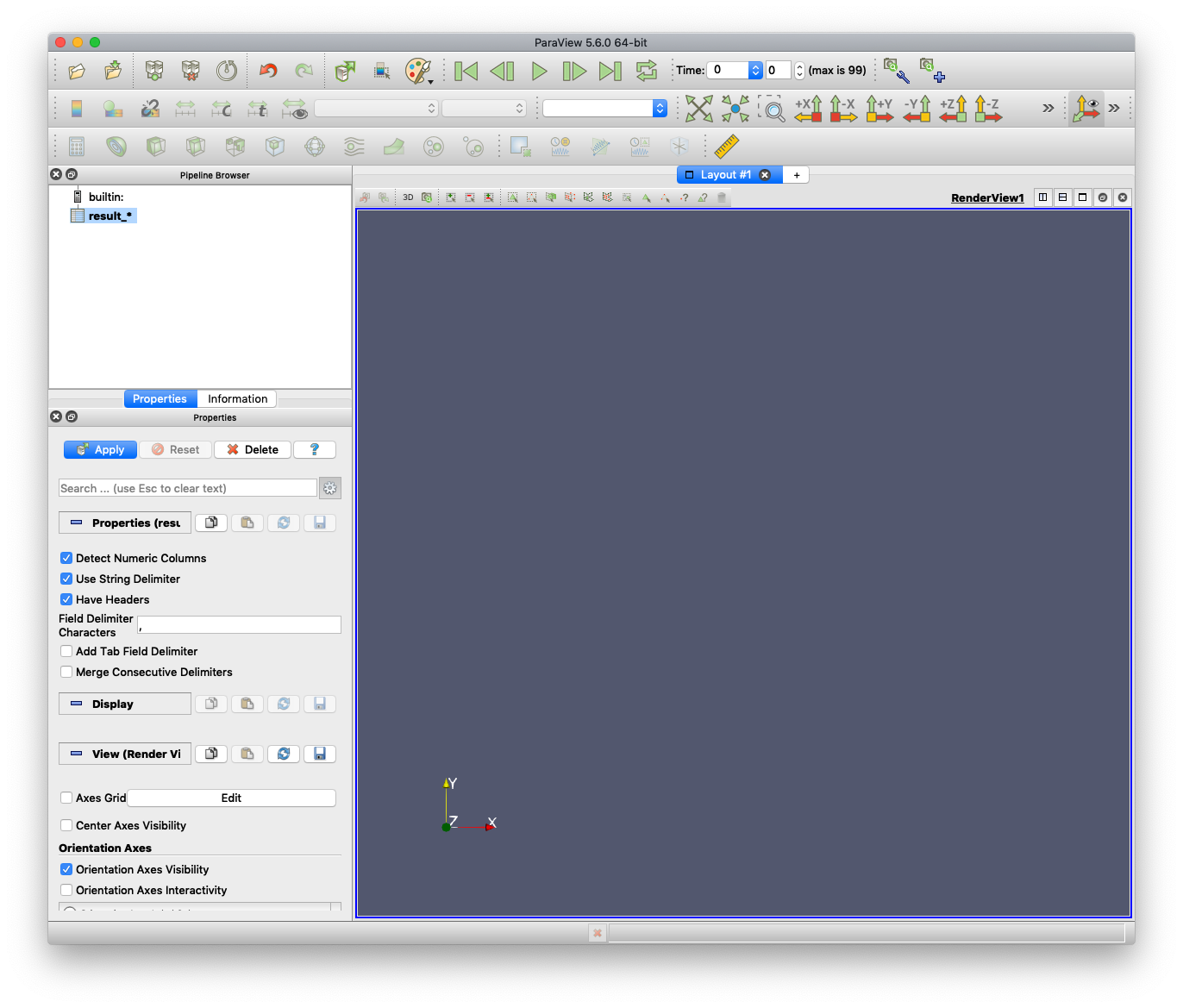
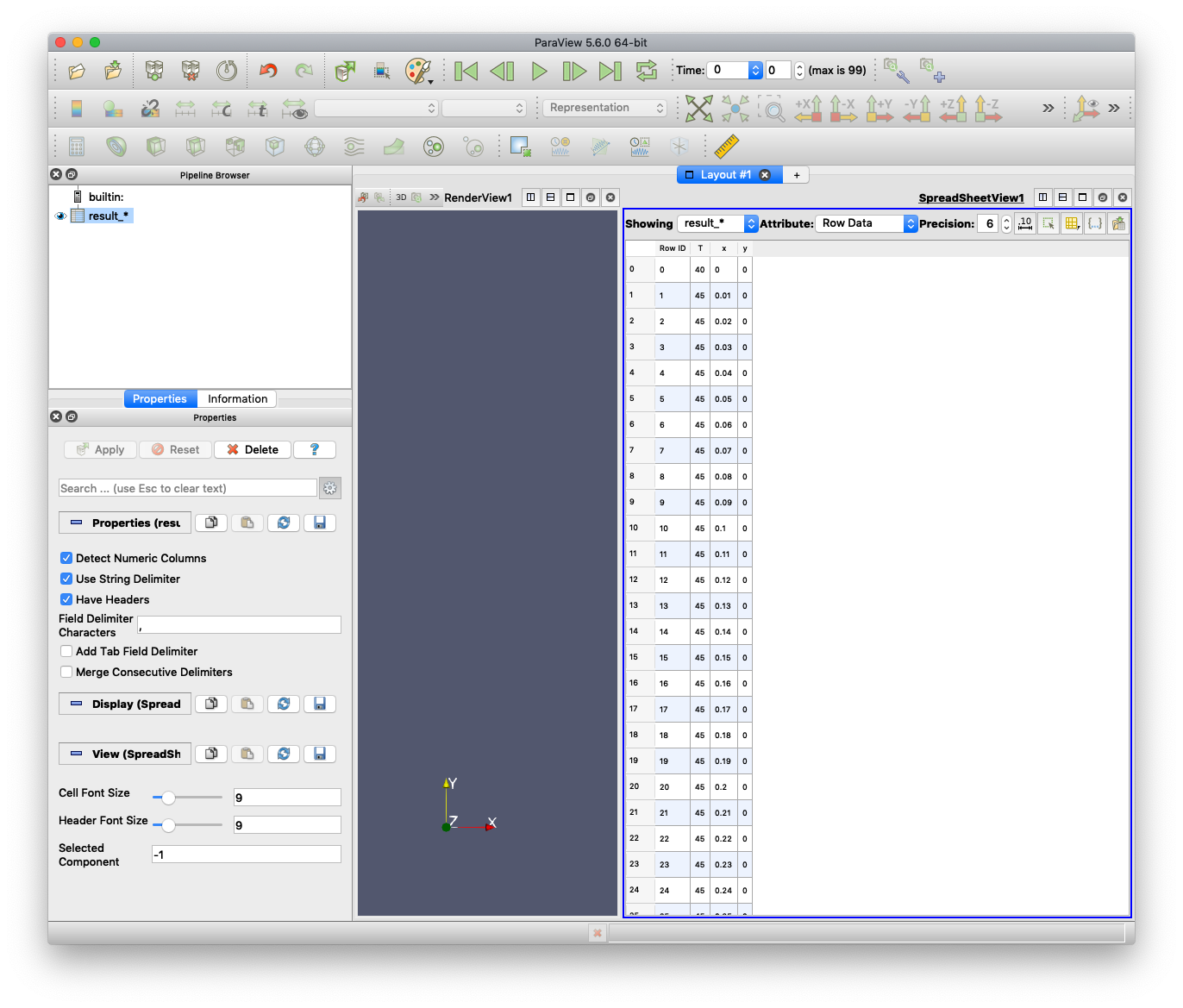
画面右側に,CSVファイルの中身が表示されます. また,画面左上の "Pipeline Browser" に,"result_*" というアイコンが追加されます. (名前は読み込んだCSVファイル名によって変わります)
新しいビューを開くため,"Layout #1" の横にある, "+" ボタンをクリックしてください.
"Render View" ボタンをクリックしましょう.
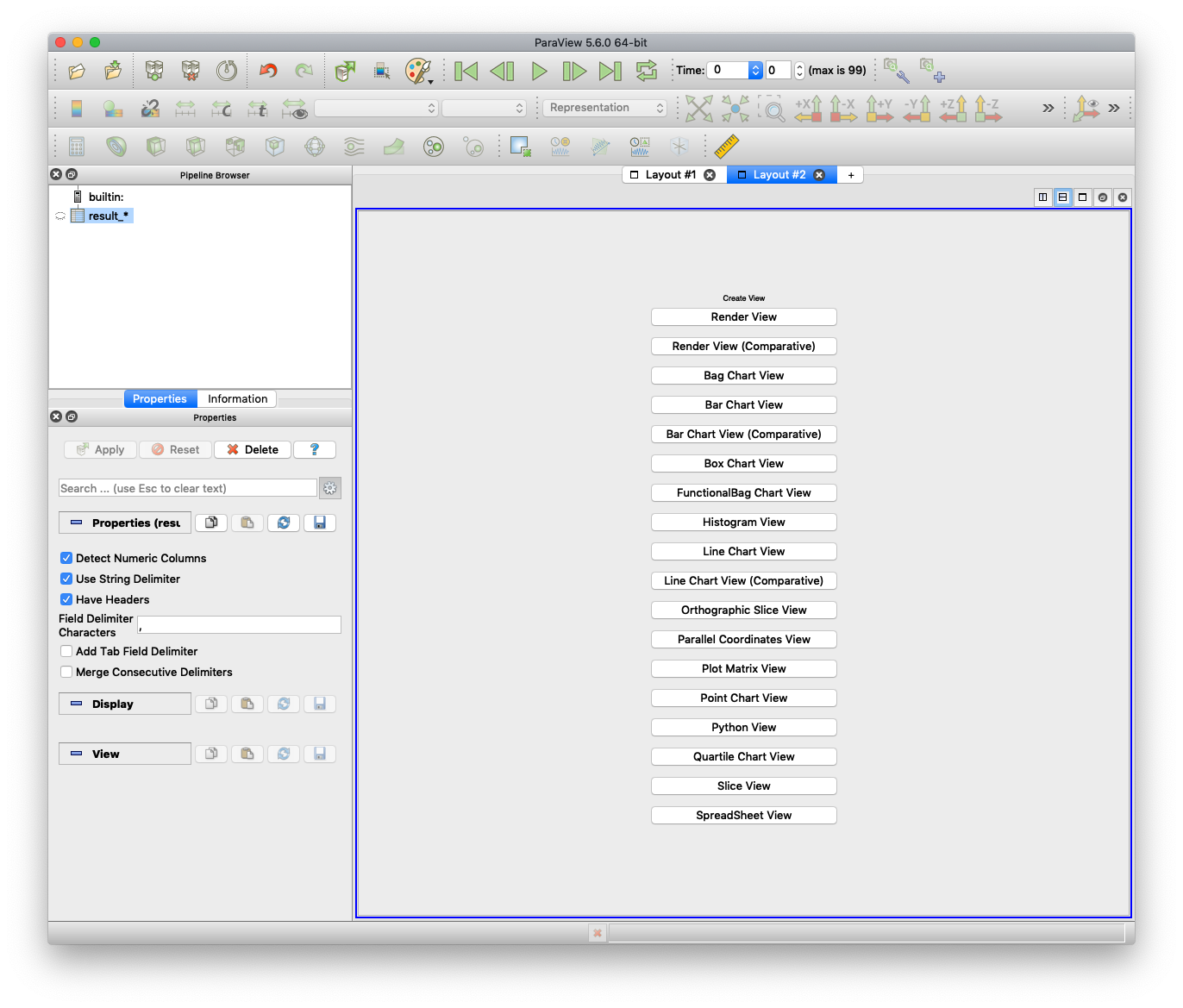
空のビューが開きます.画面左上の "Pipeline Browser" にある,"result_*" という アイコンを右クリックし,"Add Filter" -> "Alphabetical" -> "Table To Points" を選んでください.
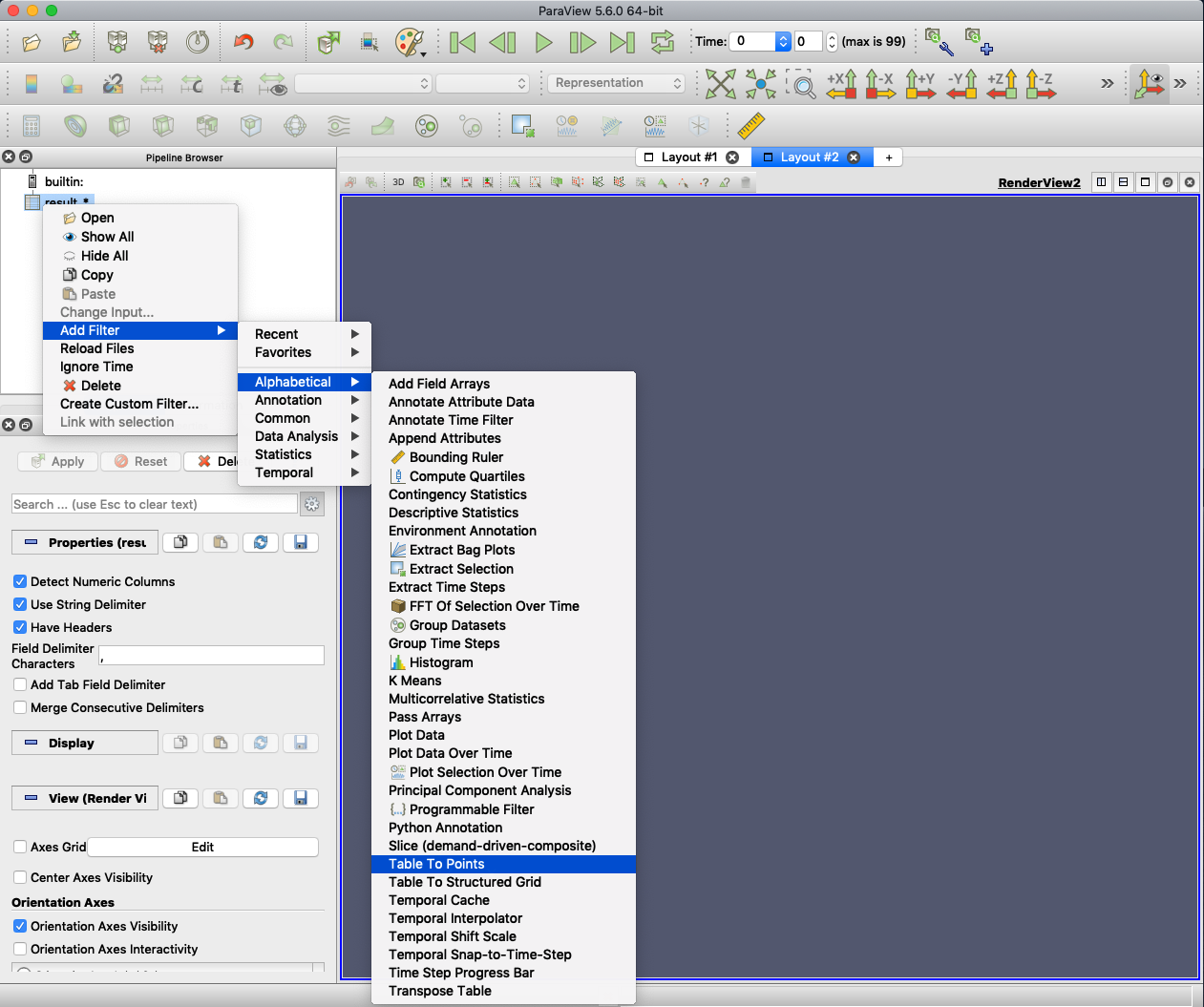
"Pipeline Browser" に,"TableToPints1" というアイコンが追加されます.
ウィンドウ左下の "Properties" タブで下記の設定を行ってください.
- "Properties" セクション
- "X Column": "T" を "x" に変更
- "Y Column": "T" を "y" に変更
- "Z Column": "T" を "x" に変更
- "2D Points" をチェック
- "Coloring" セクション
- "Solid Color" を "T" に変更
- "Use Separate Color Map" をクリック
- "Styling" セクション
- "Point Size" を3に変更
"Apply" ボタンを押してください. また,"Pipeline Browser" の "TableToPints1" の横の目のアイコンをクリックし,目が開いた状態にしてください.
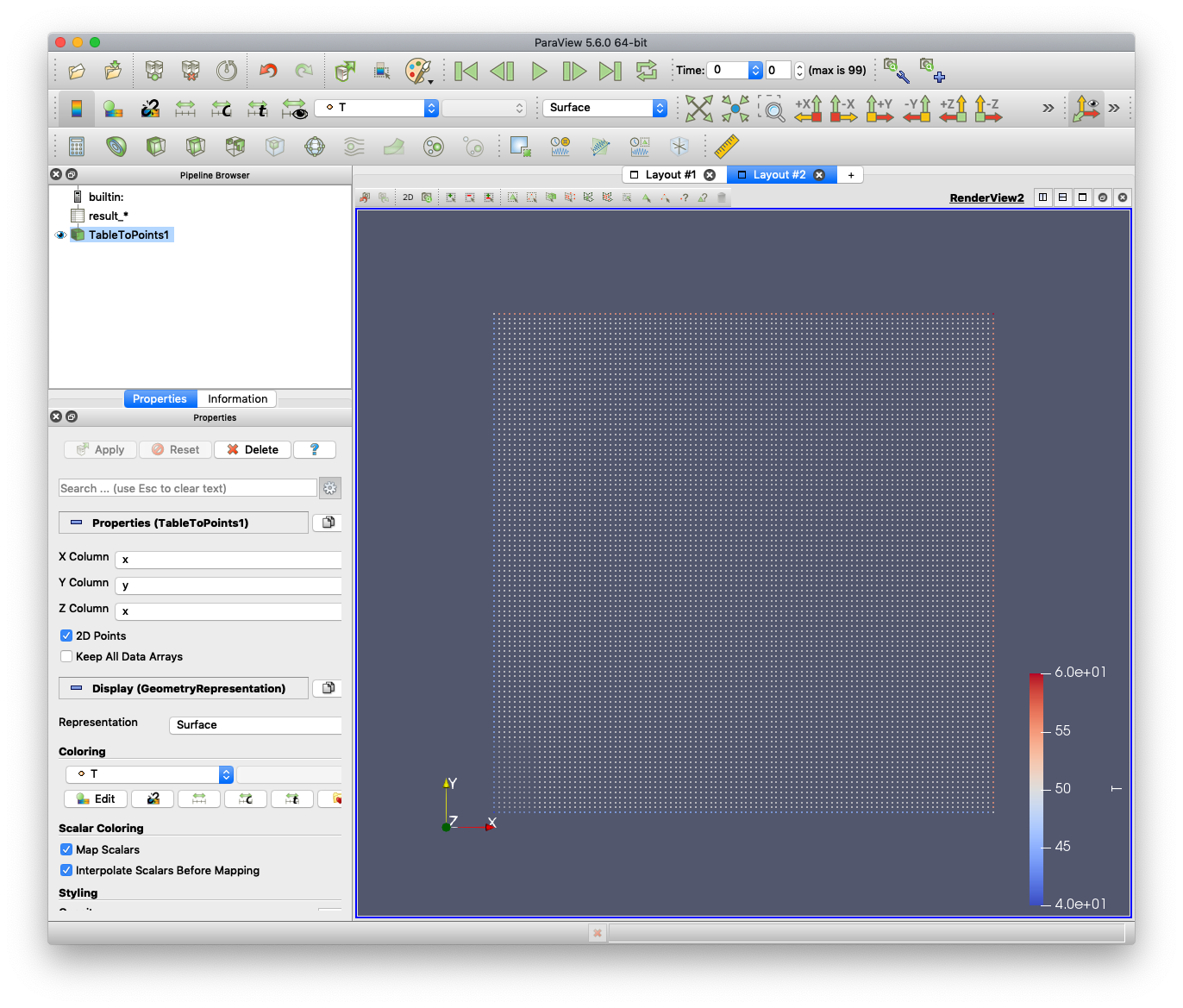
シミュレーション結果が可視化されます.画面上の再生ボタンを押すと,時間経過とともに熱が伝導していく様子がアニメーション表示されます.